He entrenado una IA para generar imágenes de mí y estos son los impresionantes resultados

Llevo meses siguiendo la actualidad de las IAs de generación de imágenes con entradas de texto. Desde Dall-E, hasta Stable Diffusion y he conseguido entrenar una versión de esta última para que me reconozca y pueda generar imágenes conmigo. Lo mejor: tú también puedes hacerlo gratis.
La evolución de las inteligencias artificiales generativas es impresionante y es que en cuestión de meses hemos visto el nacimiento de las mismas y la llegada incluso de inteligencias artificiales que completan imágenes o incluso que generan vídeos.
Hasta hace unos meses sólo era posible hacer estos procesos en local si disponíamos de GPUs NVIDIA muy potentes con mínimo 24 GB de memoria gráfica. Es decir, solo al alcance de unos pocos.
Sin embargo, la llegada de Stable Diffusion como alternativa libre ha hecho que podamos hacer uso de la misma desde navegador web con ejecución remota e incluso la llegada de aplicaciones que requieren mucha menos máquina.
De hecho, nosotros ya llevamos un tiempo utilizando una versión para Mac para M1 que es capaz de funcionar gracias al sistema de memoria compartida con desde solo 8 GB de RAM, aunque recomiendan 16 GB.
¿Quieres saber cómo puedes utilizar Stable Diffusion gratis? Y para rizar el rizo, ¿sabes que puedes entrenar la IA para que te reconozca como personaje y generar imágenes basadas en ti (o en quien quieras? Veamos cómo hacerlo en poco menos de 1 hora.
Generación de imágenes por IA con Stable Diffusion:
- Opciones para generar imágenes IA
- Conceptos básicos de Stable Diffusion
- Cómo usar Stable Diffusion y cómo conseguir la imagen que quieres
- Entrena Stable Diffusion para que te reconozca
Todos los caminos IA llevan a Roma
Desde instalaciones en local en un ordenador Windows en el que hemos tenido que crear entornos de desarrollo Python, solucionar incompatibilidades entre distintas versiones de paquetes hasta lo que hoy día tenemos: instalar una aplicación y que se configure solo a golpe de click.
A grosso modo podemos diferenciar dos modos de utilizar Stable Diffusion. Uno es online, con servicios ya funcionales como la propia demo disponible en Hugging Face o bien Hotpot.ai.
También podremos hacer uso de cuadernos Google Colab, que es como procedemos en este caso, creando online nuestra propia versión de la Inteligencia artificial de Stable Diffusion.
El segundo método es offline o en local, los archivos se generan en tu máquina y quedan para que puedas utilizarlos en local como aplicación independiente. De hecho hemos visto ya plugins para Photoshop y otras aplicaciones de retoque.
Si queremos usar el método de generación en local podemos utilizar aplicaciones como NMKD Stable Diffusion GUI para Windows (descargar). En este caso necesitamos una GPU NVIDIA, el mínimo exigido es de la generación Maxwell (familia GTX900) con 4 GB de memoria.
Se recomienda un mínimo de una GPU de la generación Pascal (familia GTX1000) con 8 GB para tener un rendimiento de generación decente y como recomendación para uso ágil una RTX con 24 GB de memoria de vídeo.
El tiempo de generación de imagen dependerá casi más de la cantidad y tipo de memoria de vídeo de tu GPU que del modelo.
Si eres usuario de ordenadores Apple tienes disponible las apps Diffusion Bee (descargar) o Charl-e (descargar) para Mac OS y como requisito tenemos que tienes que tener un ordenador con procesador Apple M1 / M2. Se recomienda mínimo de 16 GB de RAM, aunque con un equipo de 8 GB podría funcionar.
Conceptos básicos antes de usar la IA para generar imágenes
Estas aplicaciones tienen unas interfaces gráficas sencillas en las que podemos modificar distintos factores a la hora de generar imágenes. El concepto es sencillo, introducimos el concepto de la imagen que buscamos de manera lo más definido posible, en inglés eso sí.
Cada aplicación es ligeramente distinta, pero todas coinciden en los ajustes básicos. Tenemos que ajustar los parámetros de la resolución, por defecto se generan imágenes 512 x 512 px.
Podemos elegir los pasos de iteración (Steps) se recomiendan entre 40 y 50 para mayor detalle, pero más paso es más tiempo para generarlas.
También podemos elegir el número de imágenes que queremos que nos genere, suele generarse una, y no es un proceso paralelizable, si eliges 4 imágenes, según acaba la primera, empieza con la segunda y así sucesivamente.
Hay que tener en cuenta también el modelo checkpoint a usar, muchas aplicaciones lo descargan automáticamente, por lo que quizá sea algo transparente para ti. Este modelo es un archivo .ckpt en el que se encuentra toda la información de la IA ya entrenada por Hugging Face, suele pesar unos 4 GB.
Otro de los puntos es ajustar la semilla (seed) con la que empieza la iteración IA hasta llegar a generar la imagen final. Y el valor de guía o Guidance Scale es el valor con el que ajustamos cuánto se ajusta a nuestra descripción sobre la imagen generada.
Hay más valores para los que os remito al readme.md de Stable Diffusion aunque ya decimos que para una generación básica no necesitas más.
Usando Stable Diffusion, sensación de volver a los primeros días de Internet
Ahora que ya tenemos nuestra aplicación instalada, con el modelo también instalado, llega el momento del primer uso. Nos encontramos ante un campo en blanco en el que podemos introducir cualquier frase que se nos ocurra para que un ordenador cree un dibujo.
Esta es la misma sensación que recuerdo en mis primeros días de Internet, hablo de época años 90, módem y cuando viví el nacimiento de Google como buscador web. ¿Qué busco? O en este caso: ¿Qué quiero que dibuje?
Lo que queremos que genere (en inglés), modificador 1, ... , modificador XX
Tenemos que introducir en inglés lo que queremos que dibuje, de manera lo más detallada posible. De hecho, además, podemos dejar constancia de modificadores después de comas para comentar que lo dibuje como si pintase algún pintor conocido (by Van Gogh), o si queremos que sea un retrato (portrait) o fotografía (Photoshoot).
| Ejemplo de modificadores | |
|---|---|
| Cámara | Aerial View | Canon50 | Cinematic | Close-up Color Grading | Dramatic | Film Grain | Fisheye Lens Glamor Shot | Golden Hour | HD | Landscape Lens Flare | Macro | Polaroid | Photoshoot Portrait | Studio Lighting | Vintage | War Photography White Balance | Wildlife Photography |
| Estilo de dibujo | Cel Shading | Children's Drawing | Crosshatch | Sketch Detailed and Intricate | Doodle | Dot Art | Line Art |
| Estilo visual | 2D | 8-bit | 16-bit | Anaglyph Anime | Art Nouveau | Bauhaus Baroque | CGI | Cartoon | Comic Book Concept Art | Constructivist | Expressionist Figurative | Hard Edge Painting | Manga Modern Art Mosaic | Mural | Realistic Photo | Watercolor | Romantic | Street Art |
| Color | Cold Color Palette | Colorful | Dynamic Lighting Electric Colors | Infrared | Pastel Neon | Synthwave | Warm Color Palette |
| Emociones | Bitter | Disgusted | Embarrassed Evil | Excited | Serene | Sad Lonely | Horrifying | Happy | Funny Surprised | Melancholic | Angry | Fear |
| Estilo por autor | by Pixar Animation Studios | by Rembrandt | by Pablo Picasso by Michelangelo | by Leonardo da Vinci | by Johannes Vermeer by HP Lovecraft | by Vincent van Gogh | by Wes Anderson |
Evidentemente no son los únicos modificadores, de hecho, podríamos decir que estamos ante un abanico de posibilidades por descubrir.
Aquí casi os dejamos con las webs arthub.ai o Lexica.art donde los usuarios suben imágenes generadas y se muestran junto con las entradas de texto que las han generado (prompts).
El modus operandi de generación es simple, aunque seguramente para conseguir un resultado decente y que se acerque tengas que acabar probando a modo de ensayo y error a modificar la entrada de texto.
De hecho en Computerhoy ya habéis visto imágenes generadas por IA en la portada de noticias como la de la misión DART de la NASA o bien la de Elon Musk y el servicio Starlink para aviones.
Retomamos nuestro tema: Vamos a probar a generar una imagen de una calabaza de Halloween en un escritorio, luego lo modificamos para que sea verde y posteriormente para que tenga acabado como si hubiera sido pintado como Van Gogh.
Para ello hemos usado siempre la misma semilla para empezar a generar con las mismas condiciones de origen a la hora de dejar a la IA que empiece a iterar.
halloween pumpkin on a desk, HD
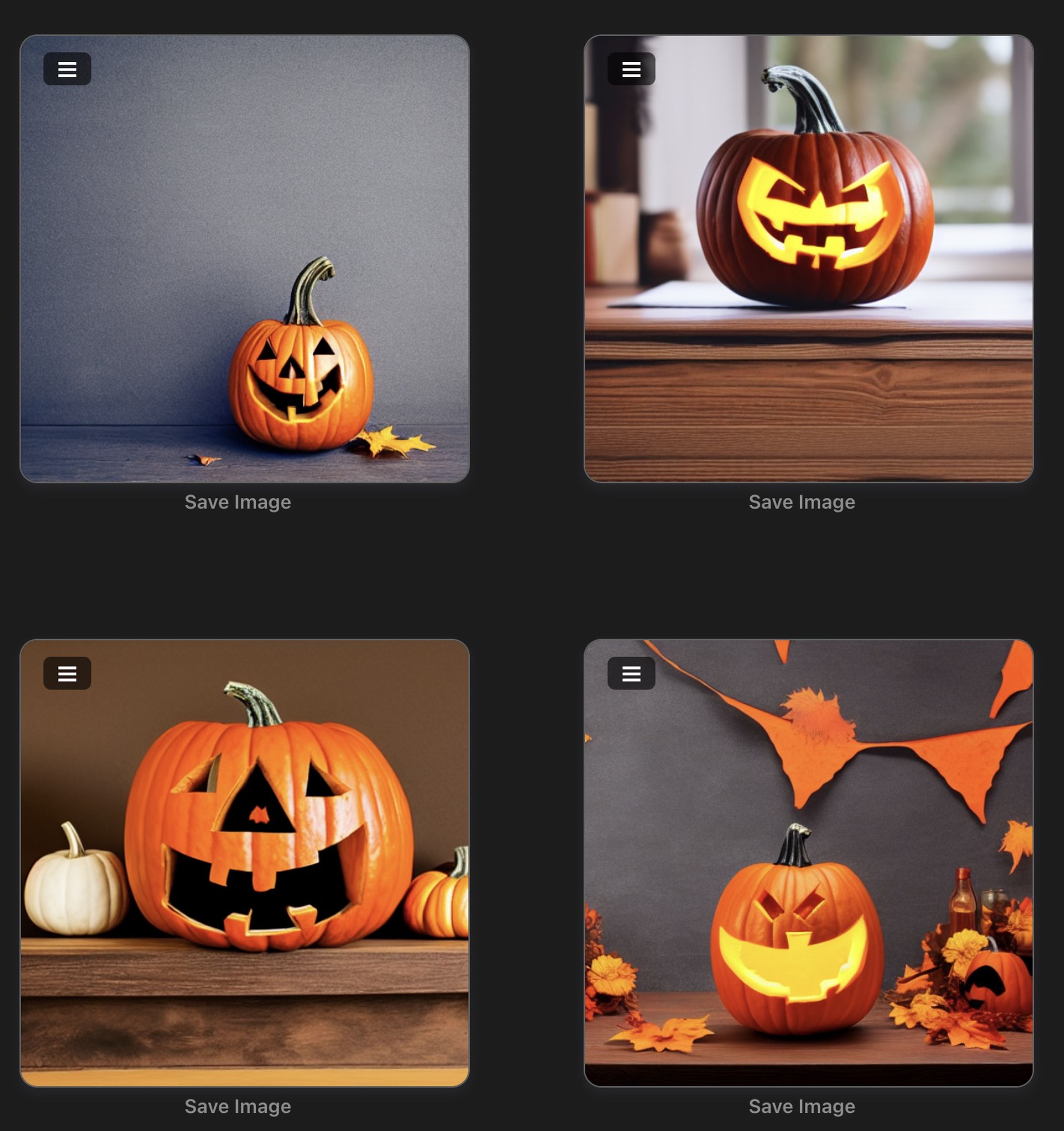
green halloween pumpkin on a desk, HD
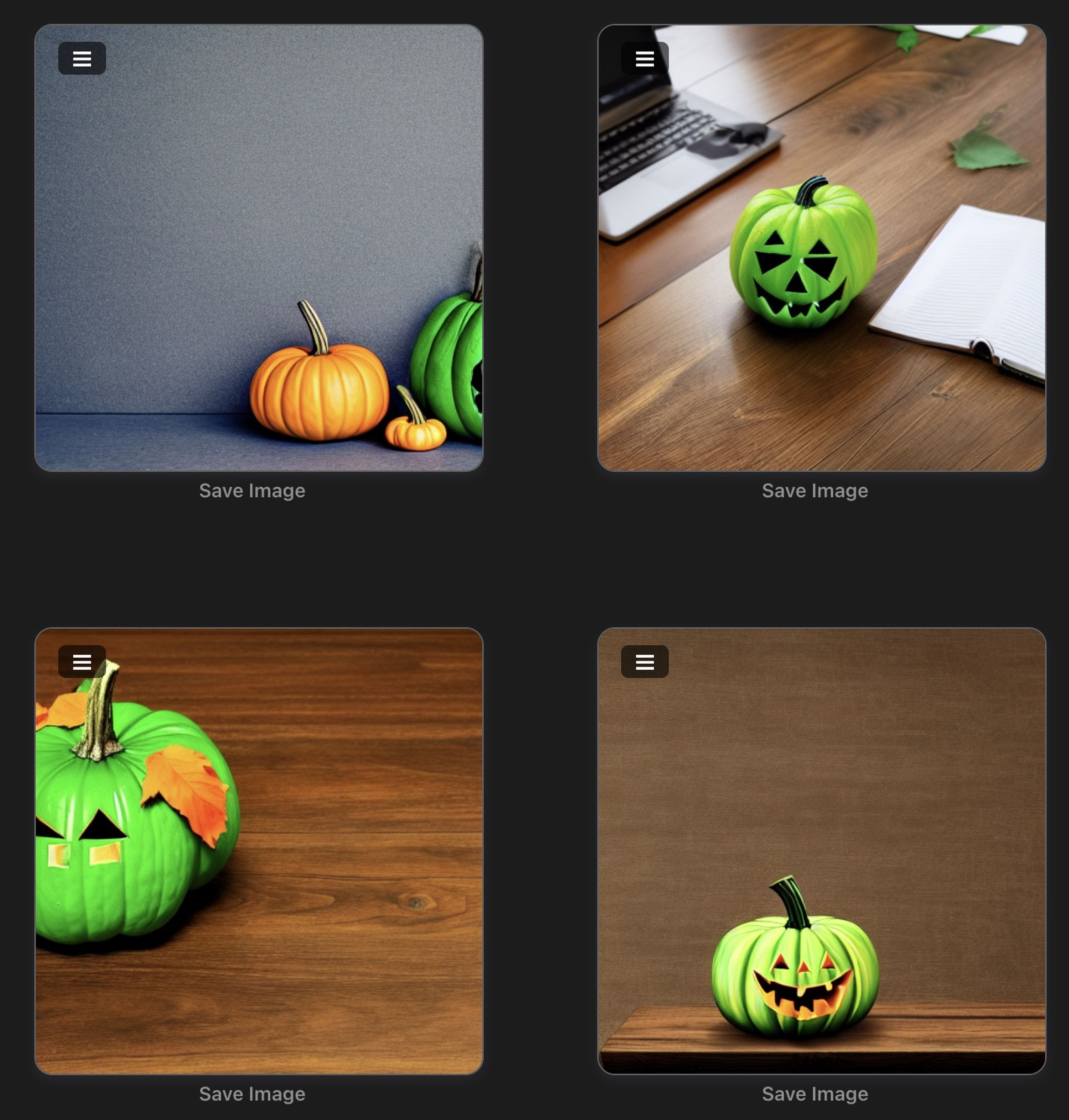
green halloween pumpkin on a desk, by Vincent Van Gogh, HD

Hasta aquí todo correcto, de hecho el archivo checkpoint que en el día que redacto este artículo va por la versión 1.5 ya reconoce millones de objetos, actores, estilos, animales.
De hecho aquí os dejamos unos ejemplos ya más elaborados y perfectamente reconocibles:


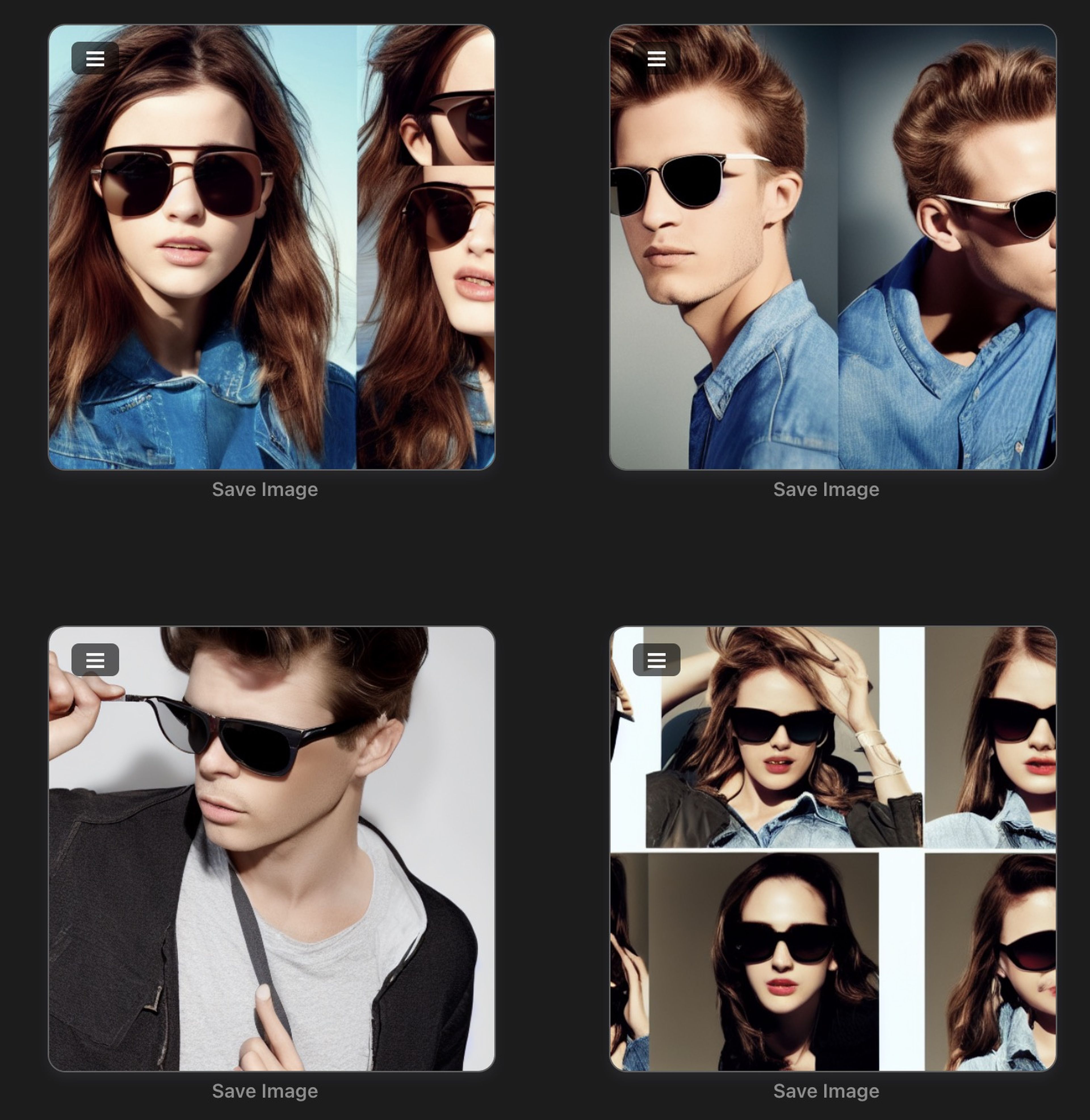
Pero, ¿y si quieres que reconozca a una persona con la que no ha sido entrenada en concreto?
Existen métodos como inpainting que permiten cambiar una parte de una imagen, o realizar una mezcla de dos imágenes cambiando la ponderación de una u otra imagen, lo que se conoce como img2img. Pero son métodos avanzados de retoque que, si os interesa, trataremos por separado.
Pero los resultados no son todo lo buenos que podrían ser, ya que al final acabamos parcheando de una u otra manera una imagen. Entonces, ¿es posible que la IA genere una imagen completa de una persona que no sea personaje público?
La respuesta es, simple, al igual que Hugging Face ha entrenado la IA para generar su modelo ckpt de más de 4GB (más de 7 GB en el más detallado) nosotros podemos entrenar la IA para que nos reconozca.
Entrenando a la IA, resultados impresionantes en 1 hora
Aquí no voy a extenderme demasiado ya que para entrenar la IA necesitaríamos de una GPU y un ordenador muy potente para conseguir concluir la tarea en un tiempo razonable.
Es por ello que están surgiendo alternativas de computación en la nube. Hay muchos cuadernos de Google Colab en los que se facilita una guía paso a paso para poder entrenar la IA con entre 15 y 20 imágenes de la persona, animal u objeto que queramos.
¿Qué es Google Colab? Es un servicio que ofrece Google en el que podemos usar sus máquinas para ejecutar código y software en la nube con equipos lo suficientemente potentes como para realizar esta tarea incluso desde la versión gratuita (no Pro).
Dreambooth IA es la herramienta de Hugging Face con la que la compañía permite crear imágenes online. Tan solo tenemos que entrenarla y os vamos a dejar con el Google Colab, adaptación de Carlos Santana (@dotcsv) de un notebook Colab de TheLastBen.
Para ello y tal como él explica en este vídeo que os dejamos a continuación, tan solo tenemos que ir ejecutando paso a paso y esperar que se vayan completando las instrucciones.
Yo he seguido los pasos y en menos de 1 hora funcionando tras realizar los primeros pasos, conseguimos nuestro archivo ckpt modificado con el entreno para que nos reconozca.
Tenemos que conectarnos y que nos asignen recursos con GPU, debido a que es un servicio gratuito, la mejor hora para que no esté saturado es la tarde / tarde noche española.
Durante la configuración inicial, tenemos que dar acceso al Google Colab a nuestro almacenamiento de Google Drive y modificar algunos campos como el término para que la IA entienda que nos referimos a mi cuando escribimos la entrada de texto.
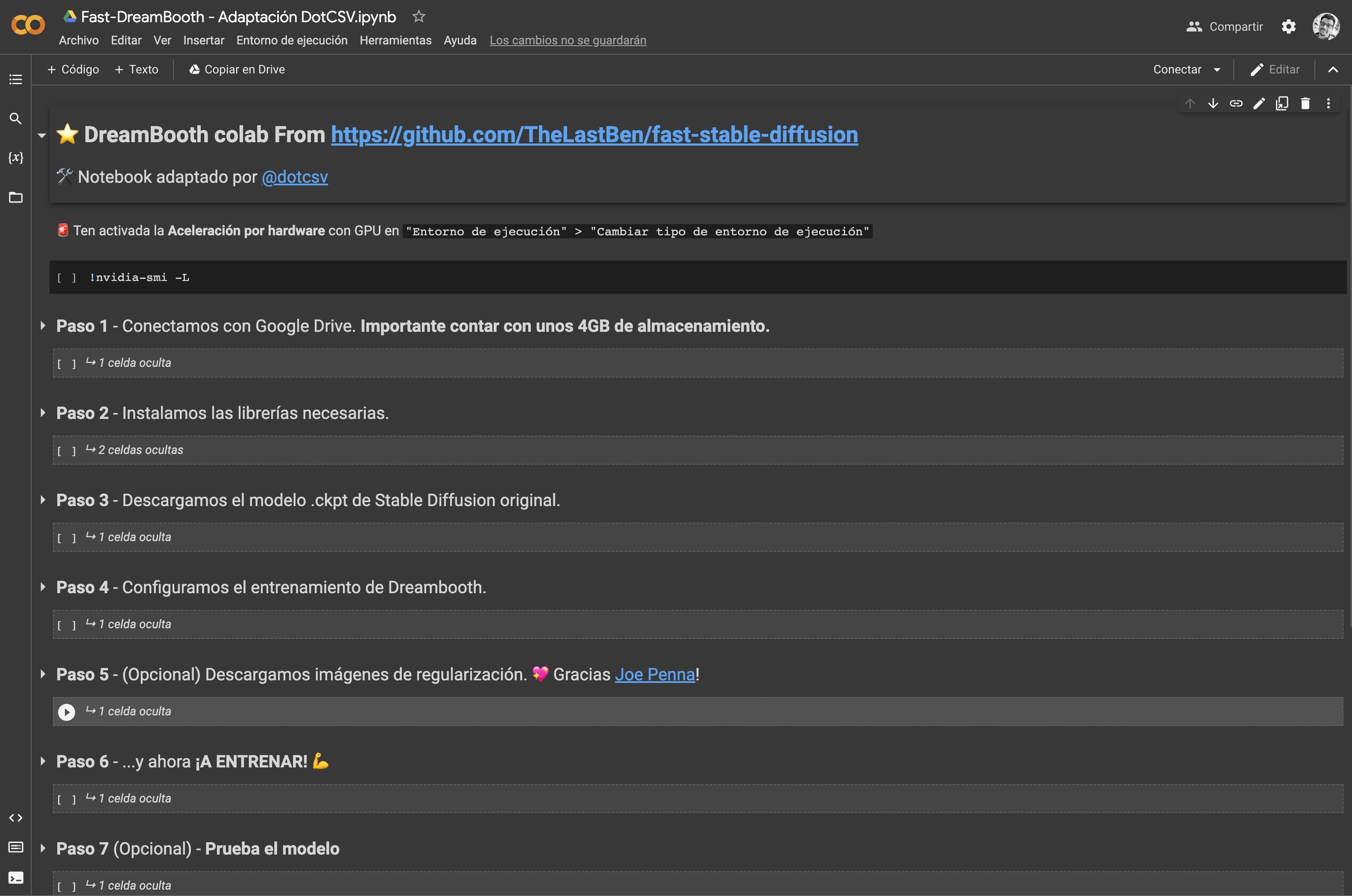
El uso es sencillo tan solo tenemos que ir dando al triangulito de la izquierda de cada paso que desplegará distintos subpasos. Tras eso ir dando al Play , en orden, y esperar a que aparezca un tick verde (se haya ejecutado correctamente).
En el vídeo de @dotcsv nos va guiando por distintos campos que tenemos que rellenar, por ejemplo el término para nuestro modelo entrenado: Yo he metido "Matu" como término o token, y como recomendación deberíamos evitar términos que puedan confundirse con personajes o conceptos ya existentes.
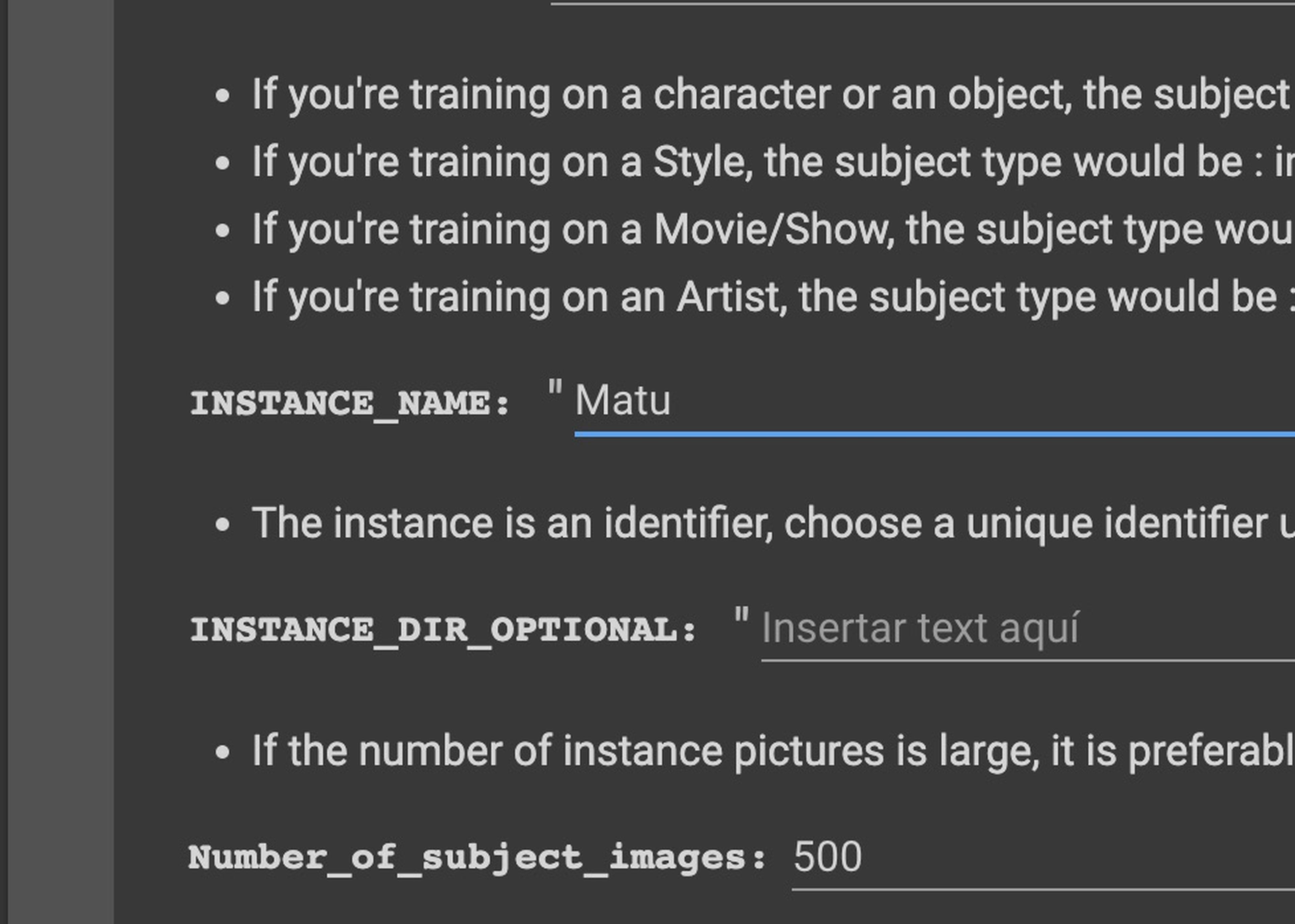
He utilizado 18 imágenes mías que tienes que ajustar previamente a resolución 1:1 de 512 x 512 px y a ser posible que sean variadas de primer plano, torso y cuerpo entero con distinta ropa. También hemos elegido 1.600 pasos de entrenamiento, que es lo recomendado.
Una vez acabado el entrenamiento -alrededor de 58 minutos-(dependerá de la GPU que te asigne Google), tendremos nuestro archivo términoelegido.ckpt en la raíz de tu Google Drive. Aviso de que pesa más de 4 GB y tendrás que tener ese espacio libre o no podrá escribir el modelo entrenado final.
En el notebook de @dotcsv ha añadido un último paso en el que se genera una interfaz para poder probar a generar imágenes con nuestro archivo modificado checkpoint. Y sirve como paso final para validar si el entrenamiento es acorde.
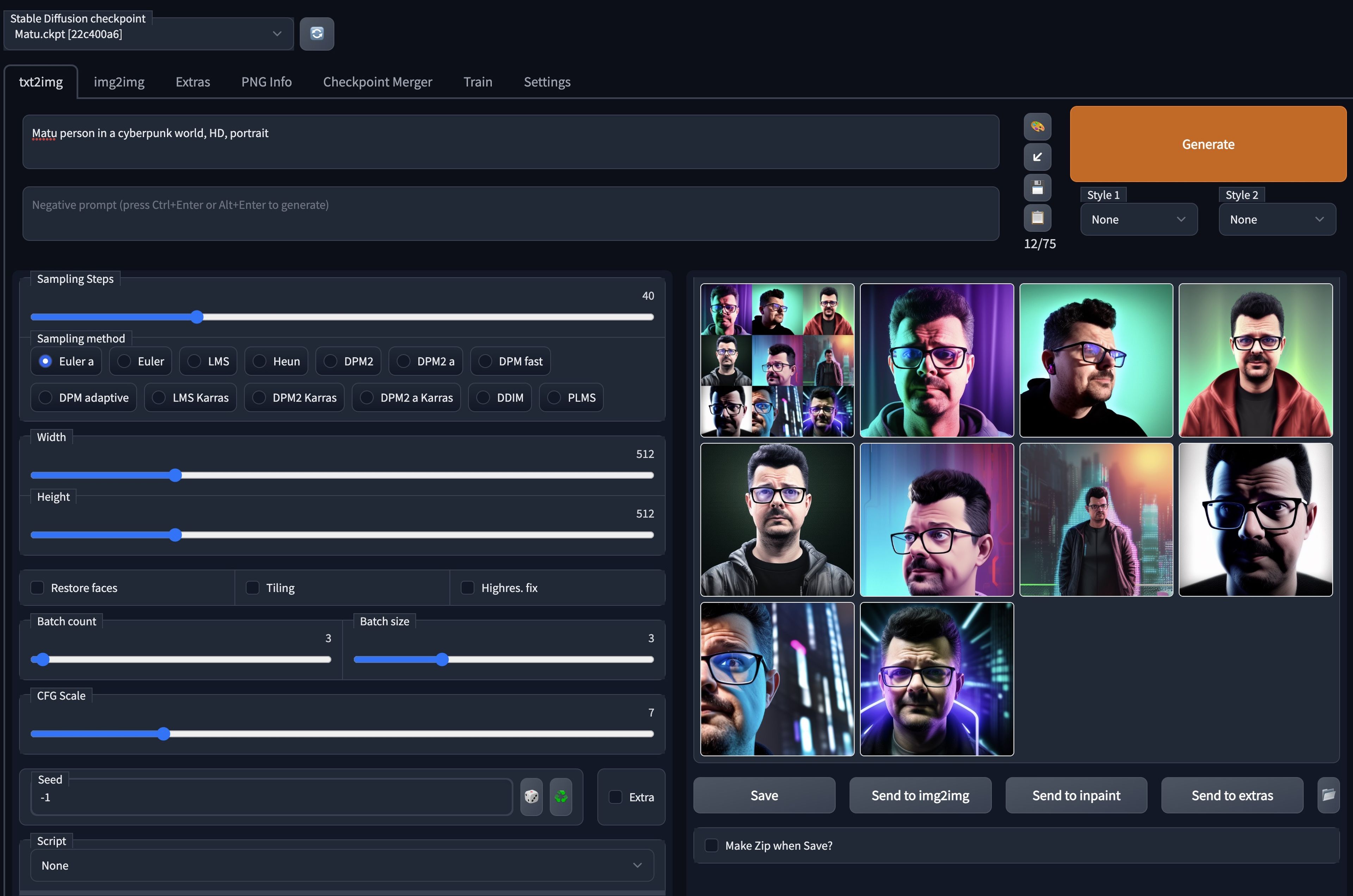
Tendremos que elegir nuestro término (token), Matu o Matu person, dentro de la petición para que la IA entienda que nos estamos refiriendo a nosotros.
No todas las imágenes son reconocibles, algunas son más o menos acertadas, pero queda claro que si hay resultados como los que hemos recibido.
Es curioso cómo al utilizar gafas con protección contra luz azul, algunas fotos las genera como si yo tuviera ojos azules, y es que, claro, los reflejos de las mismas tienen ese tinte. Aquí podéis ver los resultados originales sin comprimir.


Podremos entonces dar por bueno el modelo y descargar el archivo .ckpt para poder elegirlo en nuestra aplicación local para poder generar imágenes.
También vamos a poder montar, siempre que haya máquina disponible, este entorno web para generar imágenes desde el Google Colab Automatic1111 de TheLastBen usando nuestro modelo desde Google Drive.

En caso de que las imágenes no generen algunos resultados que nos gusten tendremos varias opciones que reajustar en nuestro proceso de entrenamiento y repetirlo tras:
- Elegir imágenesmás variadas, se recomiendan 5 de cuerpo entero, 5 de torso y 5 primeros planos de distintos ángulos y con distinta ropa y luz
- Aumentar los pasos de entrenamiento de la IA, aumentando a 2.000 - 2.500 pasos desde los 1.600 por defecto.
Estos pasos hacen que la IA se enfrente a más pasos GaN para entender el concepto que le estamos intentando enseñar.
Un sobreentrenamiento, un número muy alto, conlleva a que la IA no tenga libertad a la hora de crear y que redibuje las imágenes con las que entrenamos en los resultados en lugar de tener creaciones nuevas.
Dicho esto, solo me queda confirmaros que mis sensaciones son buenas, no es perfecto, ni lo esperaba. Pero el nivel de creación una vez te vuelcas a entender todas las posibles modificaciones de lo que le vamos pidiendo son impresionantes.

En esta imagen me reconozco perfectamente, si bien no por el traje, sí que es un gesto mío, y no tiene nada que ver con las imágenes de muestra para entrenar la IA que utilizamos.
Hasta ahora para hacer ilustraciones de este estilo se necesitaba a un artista y unas horas. O bien una foto original y un filtro. Hoy ya tenemos en cuestión de segundos las imágenes que queramos, sin necesidad ninguna foto adicional.
Evidentemente estamos ante una revolución en el mundo, como lo fue la revolución industrial, como lo serán los robots. Habrá que adaptarse, y más pronto que tarde, porque la evolución de la IA es un proceso que se mide ahora mismo en días o semanas y no en meses o años.
Otros artículos interesantes:
Descubre más sobre Jesús Maturana, autor/a de este artículo.
Conoce cómo trabajamos en Computerhoy.