La nueva IA de Microsoft simula la voz de cualquier persona con tan solo 3 segundos de audio

Microsoft acaba de presentar su nueva herramienta basada en IA para transformar texto en voz, siendo capaz de calcar a la perfección la voz humana con tan solo tres segundos de muestra.
Desde el lanzamiento del primer modelo de texto a voz (TTS), los investigadores han buscado formas de mejorar la forma en que estos sistemas generan el habla. El último modelo de Microsoft, VALL-E, supone un importante paso adelante en este aspecto.
Tan solo recordemos como hace unos días Microsoft ya anunció su idea de integrar ChatGPT dentro de sus principales soluciones como Bing, que se espera de cara a este primer trimestre de 2023. Además, todo apunta a que Microsoft también estaría desarrollando la forma para integrar ChatGPT con su paquete de programas para ofimática Office.
Sin embargo, un nuevo actor entra en el juego: la herramienta VALL-E. El jueves, investigadores de Microsoft anunciaron este nuevo modelo de IA de texto a voz que puede simular la voz de una persona cuando se le da una muestra de audio de tan solo tres segundos.
Una vez que aprende una voz específica, VALL-E puede sintetizar el audio de esa persona diciendo cualquier cosa y hacerlo de una manera que intenta conservar el tono de la persona que habla.
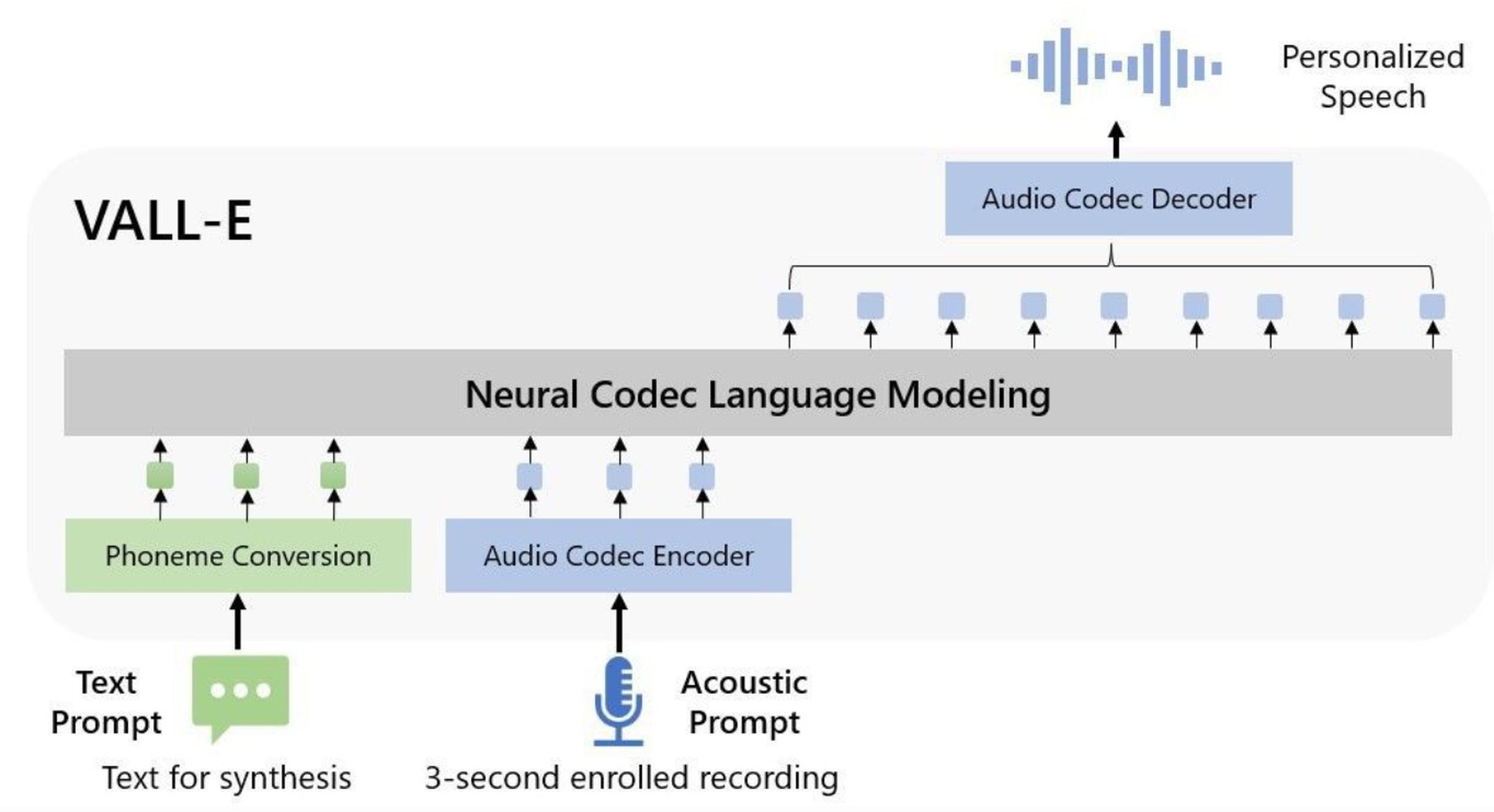
Así funciona la nueva IA TTS de Microsoft: VALL-E
Microsoft denomina a esta herramienta como un "modelo de lenguaje de códec neural", y se basa en una tecnología llamada EnCodec, que Meta anunció en octubre de 2022. A diferencia de otros métodos de conversión de texto en voz que suelen sintetizar el habla manipulando las formas de onda, VALL-E genera códigos de códec de audio a partir de texto e indicaciones acústicas.
Básicamente, analiza cómo suena una persona, descompone esa información gracias a EnCodec, y utiliza datos de entrenamiento para hacer coincidir lo que ha aprendido sobre cómo sonaría esa voz si pronunciara otras frases fuera de la muestra dada.
Microsoft entrenó las capacidades de síntesis de voz de VALL-E con una biblioteca de audio, creada por Meta, llamada LibriLight. Contiene 60.000 horas de habla inglesa de más de 7.000 hablantes, en su mayoría extraídas de audiolibros de dominio público de LibriVox.
En el sitio web de ejemplos de VALL-E, Microsoft ofrece docenas de muestras y audio del modelo de IA en acción por si quieres echarle un ojo. Dentro verás varias opciones: "Speaker Prompt" es el audio de tres segundos que se proporciona a VALL-E y que debe imitar; "Ground Truth" es una grabación preexistente de ese mismo orador diciendo una frase concreta con fines comparativos.
Por otro lado, "Baseline" es un ejemplo de síntesis proporcionada por un método convencional de síntesis de texto a voz, y la muestra "VALL-E" es la salida del modelo VALL-E.
Sus creadores ya valoran la posibilidad de que VALL-E pueda utilizarse para apps de conversión de texto a voz de alta calidad, edición de voz, cambiar una grabación de una persona a partir de una transcripción de texto (haciéndole decir algo que originalmente no dijo) y creación de contenidos de audio cuando se combine con otros modelos de IA generativa como GPT-3.


Redactora de Tecnología
Redactora de Tecnología, especializada en inteligencia artificial y ciberseguridad.
Otros artículos interesantes:
Conoce cómo trabajamos en Computerhoy.